DocPath: ドキュメントからの情報抽出に特化した大規模言語モデルの解説
Summarize:

これは、UiPath Researchの取り組みを紹介する記事シリーズの第一弾です。UiPath Researchは、AI能力を拡張するために成長中のAI科学者、研究者、エンジニアのチームです。私はこのチームのリーダーとして、同僚たちと共に私たちの仕事や発見を共有できることを楽しみにしています。
UiPath Researchチームの目標は、企業向けに最高のAIモデルを構築することです。我々の焦点は、実用的なAIモデルを開発するだけでなく、その能力を継続的に向上・拡張することにもあります。
シリーズの最初として、この記事ではドキュメントからの情報抽出を行う新しい大規模言語モデル(LLM)であるUiPath DocPathに焦点を当てます。
DocPathとは?
ドキュメントはビジネスにおいて広く使われており、重要な業務プロセスを運営する上で欠かせないものです。ドキュメントは、人とシステム間の効率的な情報伝達を可能にし、プロセスの標準化や重要な記録保持を助けます。しかし、その膨大な量と多様な形式(構造化、半構造化、非構造化を含む)のため、ビジネスが大量のドキュメントを迅速かつ大規模に処理することは困難でした。
これを解決するために、UiPath ResearchチームはDocPathを開発しました。この新技術はUiPath AIサミットで発表されました。
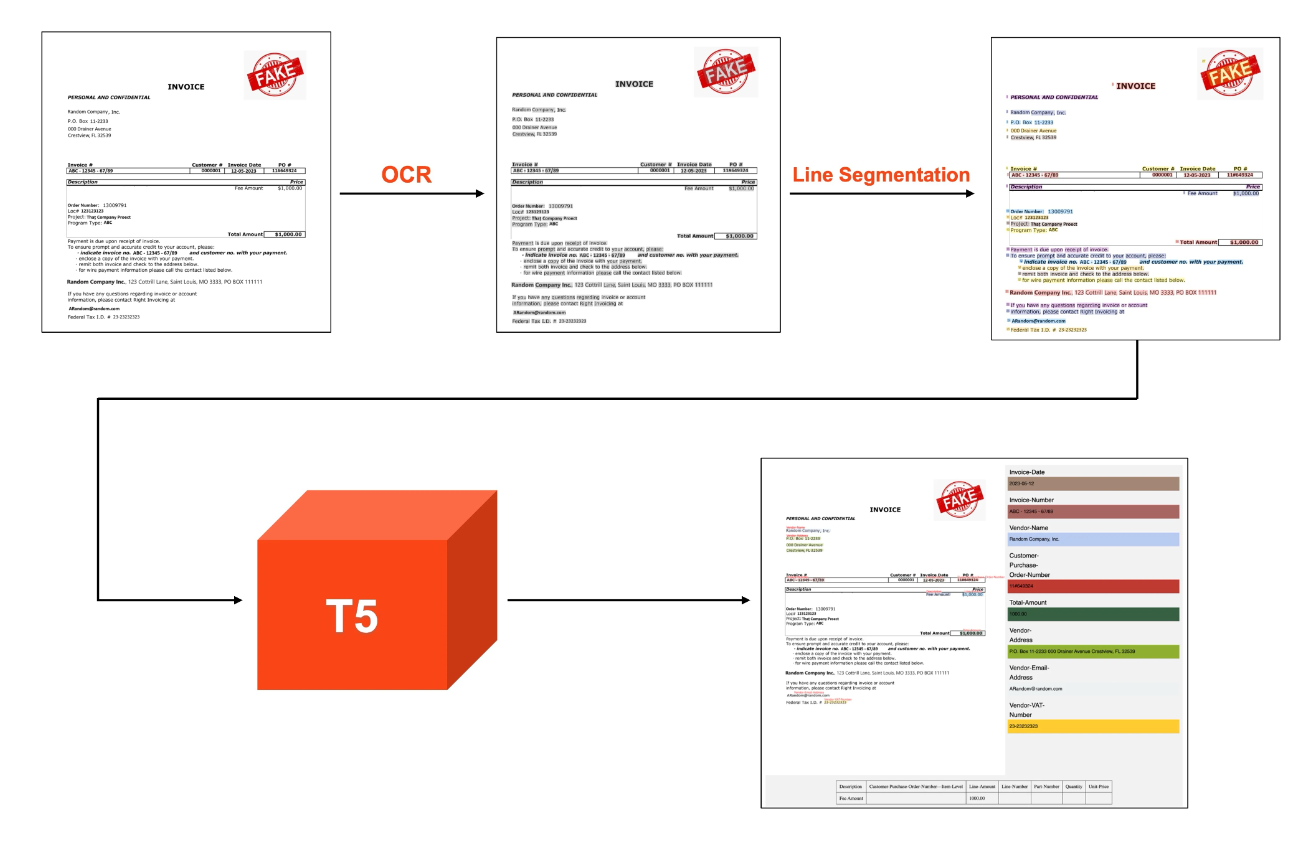
DocPathはUiPath Document Understandingの新しい基盤モデルであり、インテリジェントなドキュメント処理のためのプラットフォーム機能です。DocPathは、構造化された税務書類、請求書、発注書、財務諸表など、あらゆる種類のドキュメントをそのまま処理することができます。
DocPathの開発
OpenAIのGPTのような汎用生成AIモデルとは異なり、私たちは特定のタスク、つまりドキュメントからの情報抽出のためのモデルを構築することに重点を置きました。しかし、特定のタスクに重点を置いても、基盤モデルのアーキテクチャを選択する際には多くの選択肢がありました。デコーダーのみのアーキテクチャとエンコーダーデコーダーアーキテクチャの間で選択するには、計算効率、タスク適合性、性能の間でトレードオフが必要です。
デコーダーのみのアーキテクチャとエンコーダーデコーダーアーキテクチャの両方で実験を行いました。トレーニングデータセットには、請求書、領収書、フォーム、車両の所有権証書、発注書など、情報抽出のためにラベル付けされた10万件以上の高品質な半構造化ドキュメントが含まれています。トレーニングデータを準備するために、ドキュメントを最大シーケンス長までのシーケンスにスライスし、各ドキュメントからランダムにスライスを選択し、各スライスから抽出するフィールドのランダムなセットを選び、ドキュメントのテキスト、位置情報、および抽出するフィールドを含むプロンプト/ターゲットペアを作成しました。
Mistral 7BやLlama-2-7bなどのデコーダーのみのモデルを微調整した結果に基づいて、エンコーダーデコーダーアーキテクチャのGoogle FLAN-T5 XLモデルをDocPathの微調整のベースとして選びました。FLANバージョンのT5モデルは、非FLAN T5バージョンよりも一貫して数ポイント優れた性能を発揮することが観察されたため、選択しました。この選択にはいくつかの利点があります。
エンコーダーデコーダーモデルは、情報抽出のような限定された解決空間を持つ事実ベースのタスクで優れた性能を発揮しています。
T5は、より小さなパラメータサイズで事前トレーニングされたモデルを提供しており、大規模なバージョンのT5モデルをトレーニングする前に簡単に実験を行うことができます。
Flan-T5の指示チューニングデータセットは公開されており、事前トレーニング中に内部データの一部を利用するのに便利です。

プロンプト設計
従来のDocument Understandingモデルは、エンコーダーのみのTransformerに基づくトークン分類を使用し、固定されたスキーマのフィールドとしてトークンを分類し、フィールドタイプに基づいてスパンを結合しフィールド正規化を適用するポストプロセスロジックを適用していました。DocPathでは、モデルが構造化されたJSONのみを出力するプロンプトとコンプリートアプローチに移行しました。その結果、予測フィールドをドキュメントに戻して帰属させる新しい方法を開発する必要がありました。
これを実現するために、ドキュメント内の各OCRボックスから作成された位置トークンをプロンプトに埋め込み、モデルに位置情報を提供します。データセットからのプロンプト/ターゲットペアの例は以下の通りです:
プロンプト: "以下のテキストと座標を持つ半構造化ドキュメントから、次のフィールドを抽出してください:invoice-id、invoice-date、total、net-amount。 テキスト:<CL1> <CX23> <CY25> 請求書。 <CX25> <CY25> 235266 <CL2> <CX24><CY30> 日付 <CX34><CY32> 2023/1/24 ....."
ターゲット: {"invoice-id" : <CL1> <CX25> 235266 , "invoice-date" : <CL2> <CX34> 2023/1/24 .......}
テーブルを抽出する場合は、プロンプトに抽出する必要のある列のリストを含め、列内のすべての値とそのインスタンス番号をデコードします。例えば:
ターゲット: {"line-amount" : {"0" : "<CX27><CY34> 20", "1": "<CX29><CY38> 25"} , "description" : {"0": "<CX16><CY32> Item1", "2": "<CX13><CY32> Item2"} .........}
上記のように、特別な位置トークンは、モデルの入力の理解と基盤を強化します。<CL>トークンは、前処理中に適用された行分割アルゴリズムによって決定された行番号を表し、<CX>と<CY>は、OCRによって決定された各単語のページごとの正規化されたx座標とy座標を示します。
トークンはトークナイザーに追加され、出力でデコードされるため、DocPathは応答を正確に入力に帰属させることができます。この位置基盤は、企業における情報抽出タスクの信頼性を提供します。フィールド名に対するモデルの堅牢性をさらに向上させるために、同義語置換のようなデータ拡張技術も取り入れました。
パッチ埋め込みを使用して画像入力とレイアウト情報を取り入れることを試み、LayoutLMv3モデルの2D位置バイアスをT5のアテンションに追加しました。しかし、上記のようにプロンプト内に位置情報を直接追加する方が良い結果をもたらしました。
推論
推論を最適化し、デコードのスループットを向上させるために、いくつかの技術を実装しました。大きなテーブルや多値フィールドを扱う場合、プロンプト内のすべてのフィールドをデコードするには、プロセスの自動回帰的な特性のために時間がかかることがあります。これに対処するために、ドキュメントから抽出するフィールドのリストをバケットに分け、各バケットごとに別々のプロンプトを並行して実行し、各プロンプトの応答を統合して最終的な出力を得る方法を採用しました。さまざまな推論エンジンを試した結果、CTranslate2がデコードのスループットやコードベースへの統合の観点で最もユーザーフレンドリーで効率的であることが分かりました。フィールド値に関連するトークンのロジット値に基づいて、フィールドの信頼スコアを割り当てます。
結論
UiPath Researchは、ドキュメントからの情報抽出に特化した微調整された大規模言語モデルであるDocPathを紹介します。私たちは、新しいプロンプトアプローチを開発し、抽出されたフィールドをドキュメント上の位置に帰属させることができました。現在、より大規模なFLAN-T5モデルのバージョンやデコーダーのみのアプローチに関する実験を行っています。ドキュメントの画像ピクセルをモデルに組み込む方法についても、さらなる研究が必要です。
CommPath(ビジネスコミュニケーション処理のためのモデル)と共に、DocPathは私たちの最初の世代の微調整されたLLMの一つです。今後、他のタスクやデータタイプ向けのLLMも開発しており、それらも近い将来に発表する予定です。
これで、UiPath ResearchのDocPathに関する記事シリーズの第一弾は終了です。次回もどうぞお楽しみに。
Topics:
Document Understanding
プロダクトマーケティングマネージャー, UiPath
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.